Some coding tricks
Here are a few tricks, links or advices found here and there on the web.
Permanent link
Create mask -1 or 0 or +1 from 2 integers difference
From Sean Barrett
return (a<b) ? -1 : (a>b);
Bad as it keeps on reallocating the vector:
for ( int i = 0; i<Nbr; ++i )
{
vec.push_bask( stuff );
}
Good:
vec.reserve(Nbr);
for ( int i = 0; i<Nbr; ++i )
{
vec.push_bask( stuff );
}
Bad as it creates new useless nodes in the map's tree:
if( hashmap[idx].second != NULL )
Good:
std::map::const_iterator it = hashmap.find(idx);
if( it != hashmap.end() )
Debugging under Windows
Content of a vector : m_vector._Myfirst
Permanent link
How to debug danglings pointers (destructed pointers pointing to freed memory)
Two strategies:
- Having a tool checking allocated memory bloc's signature, do a dichotomy search by checking in several place of the code all allocated blocs.
- If a few classes are suspected, make all member functions virtual: after the class is destroyed, the pointer on the Virtual Methods Table is set to NULL, and any call to a virtual member function will crash (you mustn't have any public member variable: always use accessors/setters).
Permanent link
Convert a short int to a float between -1 et 1 using only int computations no to do Load-Hit-Store
static inline void DecompressS16ToFloat( short value, float &f ) // = float(value) / 32768.0f with exact precision
{
enum { NbrFractionBits=23, LastFractionBitS16=14, ExponentZero = 127 };
int absValue = abs(value);
int log2;
{
int v = absValue;
int shift=0;
log2 = (v > 0xFFFF) << 4; v >>= log2;
shift = (v > 0xFF ) << 3; v >>= shift; log2 |= shift;
shift = (v > 0xF ) << 2; v >>= shift; log2 |= shift;
shift = (v > 0x3 ) << 1; v >>= shift; log2 |= shift;
log2 |= (v >> 1);
}
int maskHigherBit = 1 << log2;
int maskFraction = maskHigherBit - 1;
int fraction = absValue & maskFraction;
long i = fraction << (NbrFractionBits - log2 - LastFractionBitS16 - 18); // Mantisse
i |= ( (ExponentZero - 15 + log2) << NbrFractionBits) & ((0==value) - 1) ; // Exponent
i |= (value & (1<<15)) << 16; // Sign bit
(long&) f = i;
}
Precision :
|
Integer |
float(i)/32768.0f |
DecompressS16ToFloat |
Error
|
|
0 |
0.000000 |
0.000000 |
0.000000
|
|
32767 |
0.999969 |
0.999969 |
0.000000
|
|
16383 |
0.499969 |
0.499969 |
0.000000
|
|
8191 |
0.249969 |
0.249969 |
0.000000
|
|
-8191 |
-0.249969 |
-0.249969 |
0.000000
|
|
-16383 |
-0.499969 |
-0.499969 |
0.000000
|
|
-32768 |
-1.000000 |
-1.000000 |
0.000000
|
|
25735 aka π/4 |
0.785370 |
0.785370 |
0.000000
|
static inline void DecompressU8ToFloat( unsigned char value, float &f ) // = float(value) / 256.0f with exact precision
{
enum { NbrFractionBits=23, ExponentZero = 127 };
int absValue = value;
int log2;
{
int v = absValue;
int shift=0;
log2 = (v > 0xF ) << 2; v >>= log2;
shift = (v > 0x3 ) << 1; v >>= shift; log2 |= shift;
log2 |= (v >> 1);
}
int maskHigherBit = 1 << log2;
int maskFraction = maskHigherBit - 1;
int fraction = absValue & maskFraction;
long i = fraction << (NbrFractionBits - log2); // Mantisse
i |= ( (ExponentZero - 8 + log2) << NbrFractionBits); // Exponent
i &= ((0==value) - 1);
(long&) f = i;
}
Precision :
|
Integer |
float(i)/32768.0f |
DecompressU8ToFloat |
Error
|
|
0 |
0.000000 |
0.000000 |
0.000000
|
|
63 |
0.246094 |
0.246094 |
0.000000
|
|
64 |
0.250000 |
0.250000 |
0.000000
|
|
127 |
0.496094 |
0.496094 |
0.000000
|
|
128 |
0.500000 |
0.500000 |
0.000000
|
|
200 |
0.781250 |
0.781250 |
0.000000
|
|
255 |
0.996094 |
0.996094 |
0.000000
|
Permanent link
Don't do int/float conversions
On modern CPUs, such conversions are extremely slow. The reason being that the int computation and the FPU are completely separated CPU blocs that cannot communicate directly. Exchange must go through the memory (or at least the memory cache).
On Power processors, this cause a cache flush before reading directly in memory: a Load-Hit-Store ; that's the second highest performance eater in local optimisation after the L2 cache miss.
Seen in the engine we use at work (simplified example):
for( uint i=0; i<GetNbrVertexes(); ++i )
{
u8 &color = aCppArray[i];
float colorF = (float)color;
colorF *= ratio;
color = (u8) colorf;
}
I rewrote the previous code in the following way, making it 20 times faster:
const uint nbrVertexes = GetNbrVertexes();
const u32 ratioInt = u32(ratio*65536.0f);
u8 *aColors = &*aCppArray.Begin();
for( uint i=0; i<nbrVertexes; ++i )
{
u8 &color = aColors[i];
u32 clr = color;
clr = (clr*ratioInt) >> 16;
color = (u8)clr;
}
Bit operations on floats shall be forbidden
The following code samples are forbidden in modern C++:
uint floatInt = (uint) &floatValue;
union { float f; uint i; } conv; conv.f = floatValue; return conv.i
The returned value is completely random with some compilers, and this will be more and more the case. The int computation bloc and the FPU each have their own view on the memory through their cache. One may think his cache is up to date when the other one will have updated the value.
This phenomen is named memory aliasing.
Permanent link
How to use a STL custom allocator
namespace pool_alloc {
inline void destruct(char*) {}
inline void destruct(wchar_t*) {}
template <typename T>
inline void destruct(T* t) { (void)t; t->~T(); }
}
template<typename T, typename MemMgr>
class Yac3DeStlCustomAllocator
{
static const unsigned long MaxAllocation = 102410241024;
public:
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef const T* const_pointer;
typedef T& reference;
typedef const T& const_reference;
typedef T value_type;
template <class U> struct rebind { typedef Yac3DeStlCustomAllocator other; };
Yac3DeStlCustomAllocator() throw() {}
Yac3DeStlCustomAllocator(const Yac3DeStlCustomAllocator&) throw() {}
template <class U> Yac3DeStlCustomAllocator(const Yac3DeStlCustomAllocator&) throw() {}
~Yac3DeStlCustomAllocator() throw() {}
pointer address(reference x) const { return &x; }
const_pointer address(const_reference x) const { return &x; }
pointer allocate(size_type size, const_pointer = 0)
{
if( size == 0 )
return NULL;
else
{
//T *p = (T*) malloc( size*sizeof(T) );
T *p = (T*) MemMgr::Alloc( size*sizeof(T) );
return p;
}
}
void deallocate(pointer p, size_type /n/)
{
//free(p);
MemMgr::Free(p);
}
size_type max_size() const throw() { return MaxAllocation; }
void construct(pointer p, const T& val)
{
new(static_cast(p)) T(val);
}
void destroy(pointer p)
{
pool_alloc::destruct(p);
}
bool operator ==(const Yac3DeStlCustomAllocator<T,MemMgr> & /other/)
{
return true;
}
};
Use example:
template<typename T, typename MemMgr>
class Vector : public std::vector<T, Yac3DeStlCustomAllocator<T,MemMgr>>
{
public:
Vector() {}
~Vector() {}
};
template<typename T, typename MemMgr>
class List : public std::list<T, Yac3DeStlCustomAllocator<T,MemMgr>>
{
public:
List() {}
~List() {}
};
Light to SH:
fConst1 = 4/17
fConst2 = 8/17
fConst3 = 15/17
fConst4 = 5/68
fConst5 = 15/68
void AddLightToSH ( Colour *sharm, Colour &colour, Vector &dirn )
{
sharm[0] += colour * fConst1;
sharm[1] += colour * fConst2 * dirn.x;
sharm[2] += colour * fConst2 * dirn.y;
sharm[3] += colour * fConst2 * dirn.z;
sharm[4] += colour * fConst3 * (dirn.x * dirn.z);
sharm[5] += colour * fConst3 * (dirn.z * dirn.y);
sharm[6] += colour * fConst3 * (dirn.y * dirn.x);
sharm[7] += colour * fConst4 * (3.0f * dirn.z * dirn.z - 1.0f);
sharm[8] += colour * fConst5 * (dirn.x * dirn.x - dirn.y * dirn.y);
}
Sum the sharm array for all lights involved for your object or sample.
Then for each pixel:
Colour LightNormal ( Vector &dirn )
{
Colour colour = sharm[0];
colour += sharm[1] * dirn.x;
colour += sharm[2] * dirn.y;
colour += sharm[3] * dirn.z;
colour += sharm[4] * (dirn.x * dirn.z);
colour += sharm[5] * (dirn.z * dirn.y);
colour += sharm[6] * (dirn.y * dirn.x);
colour += sharm[7] * (3.0f * dirn.z * dirn.z - 1.0f);
colour += sharm[8] * (dirn.x * dirn.x - dirn.y * dirn.y);
return colour;
}
Source : Spherical Harmonics GDCE PPT97 - Tom Forsyth and its addendum.
Jon Watte explains how to implement C++ reflection quite simply.
His source code.
Permanent link
Multiplying two 32 bits integers into a 64 bits integer
From Charles Bloom's rants: VC++ seems quite stupid at optimizing a U32 * U32 multiplication... unless one uses the Int32x32To64 macro which does exactly that the same way! Sounds really weird.
#define Int32x32To64(a, b) ((LONGLONG)((LONG)(a)) * (LONGLONG)((LONG)(b)))
Also he found out in OpenSSL sources that the Windows stdlib has very quick functions for byte rotations in integers, _lrotl and _lrotr.
A very quick sorting algorithm, in 0(kN); meaning it's faster than conventional algorithms in O(NlogN) like qsort, bubble-sort...: the Radix Sort, a quite simple idea ; here adapted by Pierre Terdiman and Chris Hecker to handle any kind of data, even floats and negative floats.
Permanent link
My favorite IDE: Visual Studio + Vim + ...
January 2008, the 24th
My favorite work environment is made up of Visual C++ 2005 or more recent for its debugger, Visual Assist for its colorization and a few refactoring tools, and the ViEmu add on to be able to use inside VC++ my favorite editor, Vim.
January 2008, the 24th
Having worked with Nant, I really start disliking this build system.
First it's incredibly slow, mostly for incremental builds. It cannot be compared to a Makefile system. Rewriting in a C# dll some dependency checking between compiled data and source animations in the game I'm working on reduced the character compilation by 5 and the total data compilation by half.
Secondly it's set up through several incredibly verbose XML file. And thirdly it doesn't support multithreading/parallel building, while it comes out of the box with Make.
January 2008, the 24th
When programming on DS, at first I thought this hardware was really crappy.
But after a while I actually started liking it: the amount of features is limited, but they're well implemented and easy to use. The whole thing is actually quite well balanced, as ie: the low screen resolution compensate the lack of 3d gpu power.
A big advantage over the PSP: the use of flash/rom memory makes loading very quick. Say bye-bye to loading screen, the DS allows streaming of level parts while the player is moving, compensating the very small number of drawable triangles in a frame.
There are annoying limitation, like the 1 bit stencil buffer. That prevents casting shadows of concave objects like character, well at least up to now (and I mean up to now).
Also one thing I dislike on the PSP is the lack of hardware clipping of polygons: polygons going too far outside of the view are just thrown away, making big holes in the rendering. Either one split polygons, hoping they'll be small enough to fit in the limits of the frustum (which is a bit wider than the camera view), or one implements a software clipping on the CPU, which will slow down the rendering. :( Also the PSP LCD screen has an incredibly high persistance compared to the DS screens.
General:
- Bad: early abstraction, before we actually know if, how and why it will have to be abstracted.
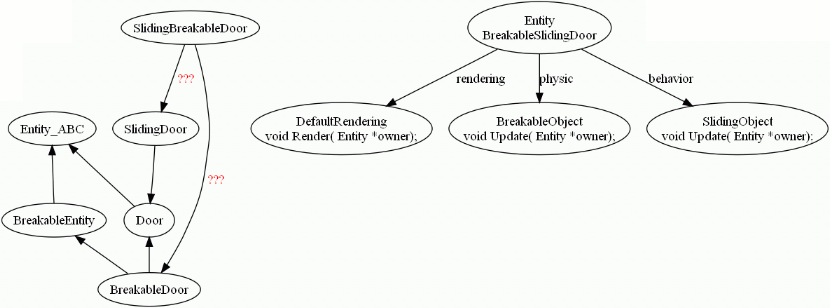
- Don't abuse polymorphism and heritage. Often a class with pointers to composants will be more generic and cleaner. Example: "shall BreakableSlidingDoor class derivate from BreakableDoor or from SlidingDoor?" ?" vs an Entity class containing pointers to several composants, which will be NULL if the component doesn't exist for a particular entity (movement, life points and stats, AI, physics, rendering...).
- "Premature optimization is the root of all evil" (by Sir Tony Hoare) is so wrong, as the true quote by Sir Tony Hoare (other page with the full quote) does prove:
We should forget about small efficiencies, say about 97 of the time: premature optimization is the root of all evil.
Early function-local optimization (like asm) is wrong. Early algorithm/application architecture optimization is good and it is a must do/have to be a good programmer. Doing it too late in the life of the project means it will be harder or impossible to do, plus it will slow down the project development. - Extreme-programming: bad name for grouping ideas that already existed previously. What creating another marketing word and why using the so negative "extreme" word?
- Peer-programming: very good for specs.
Readable code
- No too long functions (max ~ one screen / 40 lines).
- No too generic meaningless variable names: dirPlayerToTarget instead of dir.
- Don't reuse a local variable in a different way, always create a new one with an explicit name.
- Add a comment on each #else and #endif telling which #if it corresponds.
- Exit a function only at the very beginning in some inputs checking, or at the very end.
- No "C" prefix in class names. This habits comes from Microsoft to make a clear distinction between their classes and classes from other programmers. Unfortunately other programmers started using the same naming convention (in an extended Hungarian notation), making it both useless and counter-productive.
- Use standardized coding guidelines in your team, that will help sharing code. A few examples (but you'll meet lots of other conventions as each company or even each project has its own rules):
- I like the Pascal/Java notation for class and methods/functions names, and the Camel notation for variables: no '_' in the middle of the name, caps on each word of the name, except the first one in variable names: float speed, int GetSpeed().
- Member variable names should be obious. Either using a prefix (m or m_ ou autre), or a suffix. Don't use '_' prefix or suffix as C/C++ standard forbid that. Small advantage of suffixes: faster to (not) type with auto-completion ; but harder to read/catch for some people.
- Hungarian Notation: I like a very simplified notation stating only statics, globals, C arrays, and C string. No pointer/integer/float/... prefix. But each team you'll meat will have different habits, one is to changes his habits with every new job.
Permanent link
Quick inversion of a 4x3 matrix
Let's M = T * R, a 4x3 matrix.
Usually one would use a heavy method like Gauss to invert it, but watch this:
M-1=(T*R) -1=R -1*T -1=Rt*T -1
So you transpose the rotation part, you create T-1 which is a translation matrix which pos vector is the opposite of the original one, you multiply the 2 together and you're done! Pseudocode:
r.rot = transpose(M.rot);
r.pos = Vector(0,0,0);
t.rot.SetIdentity();
t.pos = -M.pos;
Minv = r*t; |
Permanent link
Vector and matrix classes, math operators
Very often you'll read that writing a class dumbly with a Vector operator +(const Vector&, const Vector& ) will create a temporary object and that it will slow down your code.
Well that is... true.
But if you define this operator as inline const Vector operator +( const Vector &a, const Vector &b ) not only most compilers (tested on PC and on PSP) will not create a temporary object, but they will also create faster assembly code (10% faster than using float arrays or temp objects and sage operators like += in my tests). Notice than the return type has to be consted. Otherwise it could be altered in another operator so the compiler won't optimize it.
Some beginner people return a reference to prevent the copy, but that's using an object after it has been destroyed, which is plain wrong and which will not always work (in a perfect world it would always crash).
Permanent link
GCC and the PreCompiled Headers (PCH)
And that's it, compilation will get at least twice faster!
Permanent link
How to cleanly use dependencies with GCC/Makefile
I've seen too many projects having 2 compilation passes: make dep then make. If one forget to relaunch make dep from time to time, dependencies can get plain wrong. The good solution: add -MD in your CFLAGS or CXXFLAGS. Recompiling a file will update its dependency file. Then add -include *.d in the end of your Makefile.
The make dep is now required only when deleting a header.
Permanent link
How to correctly indent using tabs
Indent using both tabs and spaces.
Permanent link
For those who love bits tricks
Source: Steve's 'Cute Code' collection and Sean Eron's Bit Twiddling Hacks
- Reverse all the bits in a 32 bit word:
I found this one in the Linux fortune cookie program (!)
n = ((n >> 1) & 0x55555555) | ((n << 1) & 0xaaaaaaaa) ;
n = ((n >> 2) & 0x33333333) | ((n << 2) & 0xcccccccc) ;
n = ((n >> 4) & 0x0f0f0f0f) | ((n << 4) & 0xf0f0f0f0) ;
n = ((n >> 8) & 0x00ff00ff) | ((n << 8) & 0xff00ff00) ;
n = ((n >> 16) & 0x0000ffff) | ((n << 16) & 0xffff0000) ;
- Test to see if a number is an exact power of two:
b = ((n&(n-1))==0) ;
- Zero the least significant '1' bit in a word:
n&~(n-1)
- Create a mask when a value is not zero/when a test fails:
mask = (i==0)-1
- Convert any not null number in 1, else in 0
b = !!b;
- Duff's device to unroll a loop - indenting is primordial to understand what's going on:
int a = some_number ;
int n = ( a + 4 ) / 5 ;
switch ( a 5 )
{
case 0: do
{
putchar ( '*' ) ;
case 4: putchar ( '*' ) ;
case 3: putchar ( '*' ) ;
case 2: putchar ( '*' ) ;
case 1: putchar ( '*' ) ;
} while ( --n ) ;
}
- Log 2:
r = (v > 0xFFFF) << 4; v >>= r;
shift = (v > 0xFF ) << 3; v >>= shift; r |= shift;
shift = (v > 0xF ) << 2; v >>= shift; r |= shift;
shift = (v > 0x3 ) << 1; v >>= shift; r |= shift;
r |= (v >> 1);
{kind=link}